The Challenge
I often hear a statement which worries me, especially but not exclusively in agile projects, along the lines of “we’ll make sure it works when we test it later”.
Now you may think this is an odd view coming from a man who has written testing courses, presented conference papers on testing and developed testing tools, but let me explain myself.
First up, there’s the old chestnut that the objective of testing is not to prove something works, but to find errors. All you can actually do by testing is locate problems to be fixed, although obviously if problems are hard to find, that increases confidence in your product. However the much deeper issue is that testing is commonly viewed as an alternative to properly understanding and documenting the expected behaviour of a system, and reviewing in advance whether a proposed design will deliver that behaviour. That can be a recipe for failure.
Obviously in some areas this is an acknowledged and viable trade-off. If we are exploring functional alternatives, or working in a problem space where extracting documented requirements is tricky, then agile development and testing is a powerful solution, and we accept the rework that may result where we get it wrong. Having said that, even in something like UI development it may be better to develop cheap models such as wireframes, and at least attempt to explore solution fit before we commit too much to code.
The problem is that when we come to the more fundamental architectural elements and non-functional behaviour, the dynamics change dramatically. The best way to show this is a variant of the testing “V Model”:
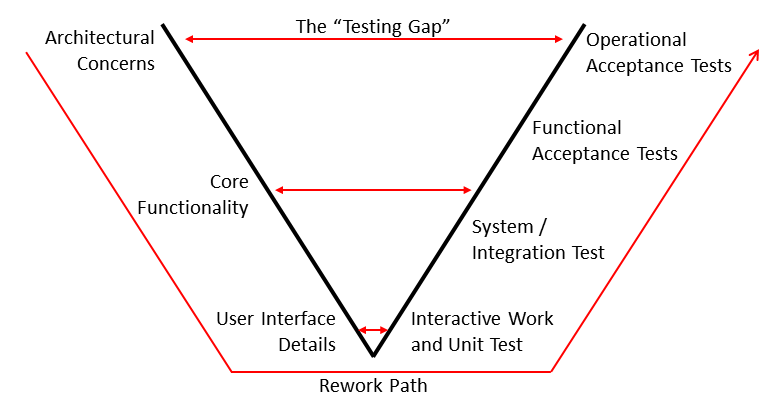
For functional details, the gap between development and testing is small, and they can quickly be reworked and retested. However some of the key architectural and non-functional aspects can only be fully tested late in the delivery process (and frequently only late in the overall programme), if at all. The “testing gap” becomes huge, the impact of any change substantial, and the rework path lengthy.
One challenge is that many non-functional tests require an environment representative of the technology and scale of the production system. If this is provided at all, it is typically late in the project, or testing has to be shoe-horned into a short window on the production system before operations commence. If that uncovers a major issue, it is simply too late.
That’s assuming that the issue is detectable. In an agile development, it may be difficult to understand “what acceptable looks like”, if there is no adequate agreed, documented definition of the expected non-functional behaviour.
The other challenge is that good non-functional testing is hard, and limited in what it can achieve. Simulating a peak load is difficult, especially with the variety of data in a real production peak. You can simulate planned and unplanned equipment failures and restarts, but by definition only predictable events. If a problem only emerges from lengthy running or a “perfect storm” event, then testing is unlikely to uncover it. Basically resilience is testable, performance may be testable, reliability isn’t. Similar considerations also apply to other non-functional aspects like security.
The Solution
The solution is to adopt an analytical and predictive approach: trying to understand, articulate and document the expected behaviour of the solution, before you build it. Importantly this is not just thinking about the solution (although thinking is vital), but thinking with models.
Models in this context take many forms. They can be diagrams, possibly based on UML, but not necessarily: for example reliability block diagrams or fault tree analyses are powerful tools to understand resilience and reliability. They can be spreadsheets, for example profiling expected transaction mixes and their relative resource requirements. They can also be active software, whether simulations of some expected behaviour, or point implementations to quantify some aspect of the solution, but the point is that their purpose is to understand the solution before a major technical commitment, not to deliver functionality. Irrespective of form all models should lend themselves to a quantitative understanding of the solution, not just “what?”, but “how much?” and “how well?”.
For example, here’s a simple redundancy scheme modelled using RelQuest, my own Visio-based fault tree analysis tool, from which we can not only understand the various combinations of failures which lead to loss of service, but the relative probability and impact (e.g. Mean Time to Repair) for each combination.
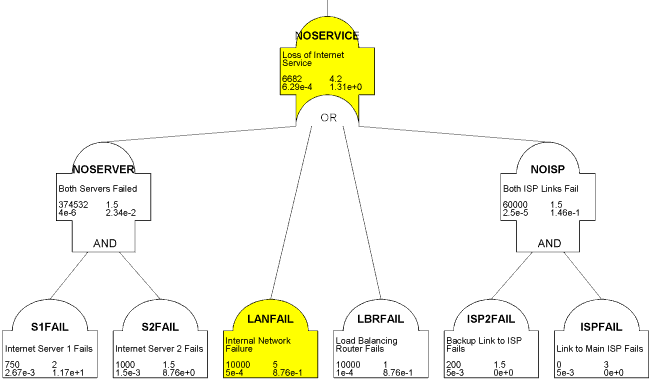
Models and simulations provide you with an early understanding of the system behaviour, so you can understand whether something should work, or not, and if not where to focus your efforts. They can be detailed, like the example fault tree above, or doing an early first pass on a platform provider’s sizing tool, but a more approximate approach may also provide value.
Numbers are your friends. I am a great fan of Fermi estimates (see the sidebar) – quick “order of magnitude” approximations to see if you have understood the key elements in a problem, and whether the answer looks viable or not.
You can easily get viable estimates of this type for performance, capacity or reliability. If the answer is “no problem”, like we can easily accommodate millions of transactions per hour on a single server and we expect thousands, then you’re probably fine. If the answer is the other way round, like the developer who proudly presented me a solution which would take 1s CPU time to do a calculation, but we needed to do a thousand a second, then the design needs to change (I got it down to 2ms, which was acceptable). If it’s marginal, then you probably need to do a more accurate model and calculation, or build a greater degree of flexibility into the solution.
Simulations or low-volume experiments may be a valid way to understand CPU, storage and memory usage, network bandwidth requirements, threading, virtualisation, and even failover behaviour. Anything which scales linearly can be measured at low volume and extrapolated, but you need to be wary of areas such as network latency or storage throughput where that may not be valid.
Ultimately anything which builds your understanding and proves that you have thought about the problems in advance is good, even if some detail may only be confirmed at later stages. The key point is that the problems become targets for analytical thinking rather than hope and prayers, and that makes them solvable.
The Conclusion
Testing on its own is absolutely necessary, but very much not sufficient. For tests to be meaningful you have to describe the predicted behaviour in advance, and for the system to have any chance of passing those tests it has to be engineered accordingly. We increasingly seek to drive functional development from written user stories and behaviour specifications. In the same way professional development must be driven by quantitative models which forecast non-functional behaviour for testing to confirm, not discover in surprise.
Sidebar – Fermi Estimates
I love Fermi estimates, named for the great Italian-American physicist Enrico Fermi, who was always doing them. These are calculations which you know have a lot of inaccuracies, but which are simple enough to do quickly and get an answer which is “sort of right” to tell you if you have correctly understood the dimensions of the problem, and if something should work, or not.
Let’s do one. This is not about computing, but is an easy example to understand the process. How much does my house weigh?
Well my house is built mainly of brick, and for the purposes of this calculation can be thought of as a rectangular block roughly 8m x 12m, and about 3m high. (I happened to have these figures, but I could always just pace it out and use 1 pace = 1m). Allow for internal walls, and you could think of my house as four slabs of brick 8m long x 3m high, and four slabs 12m long x 3m. Alternatively that’s 4 slabs 20m long, or one slab 80m long. But remember that all the walls are at least two bricks thick, so it’s like one stack of single brick 160m long and 3m high. Now I know this doesn’t take any account of windows and doors, and the open plan bit at the front, but it’s also ignoring the roof and floor slabs, and I think that will balance out quite well. Google “house brick dimensions” gives us 215mm long and 65mm high, and a typical weight of 3.5kg. Divide 160m by 0.2m (this is a Fermi approximation remember) to get 800 bricks long. At 65mm high 3 bricks on top of each other will also be about 0.2m high, so the height of our stack will be 3x3m/0.2m = 45 bricks high, call it 50. That gives us a grand total of 50×800=40,000 bricks. Now 40,000×3.5kg = 140,000kg, or 140 tons. Fermi approximations are good for at best one significant figure, so round it off to 100 tons. Bingo!
So a simple model can get you a useful answer quickly, and you may even be able to do the maths in your head. Now obviously there are a lot of guesses and approximations here, like the density of all key materials is similar, and I haven’t so far accounted for the foundations, which might be needed, and I might want to double-check the typical weight of a brick which is a key value, but I’d be surprised if the “real” answer wasn’t somewhere between 50 and 300 tons.
You can easily do the same thing to get viable “order of magnitude” figures for performance, capacity or reliability.






 Email me
Email me Others
Others Main feed (direct XML)
Main feed (direct XML)